

Photo by Alina Grubnyak on Unsplash
Lexical Analysis (Scanners) the easy way.
A look into compiler techniques


Overview
The job of a compiler is quite simple. A compiler changes a higher level language (e.g. Python, Java, C# or C++) into a lower level language which the computer understands which is the infamous binary of 1's and 0's or machine language. Now there is a long process, but super fast process before the source program is converted the the object program. In this article however, we delve into the Phases of Compilation, particularly scanning
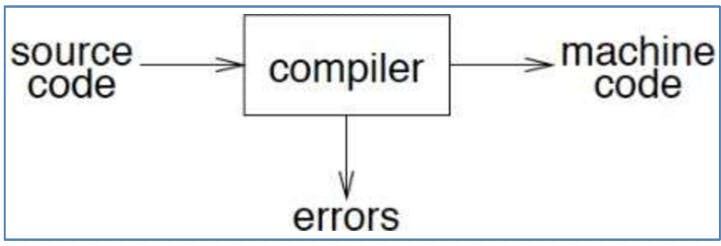
Here's where we are in the ladder Step 1) Lexical Analysis (Scanning) — receives ‘Streams of Characters’ to produce ‘Tokens’
Syntax Analysis (Parsing) — receives ‘Tokens’ to produce ‘Parse’ (Syntax Tree) Semantic Analysis — annotates the ‘Syntax Tree’ to produce ‘Abstract Syntax Tree’ Intermediate Representation — generates ‘Intermediate Code’ & Optimizer Code Optimization Code Generation - Target ‘Machine’ Code
- ~ Dr. A. Azeta*
Mnemonic | Scarlett Please Send Inter-milan COol codes
The scanning process is also known as Lexical Analysis .To demonstrate the scanning process. I will make use of a Java program also available on my https://github.com/Petrus-Nauyoma/stringtokenizer1.
Think of all the code that you write in your favourite IDE as a stream of characters. Remember, it is the job of the compiler to know the grammar and rules that defines this stream of characters anyway. The end goal is to take a program as input and map the character stream into “words”.
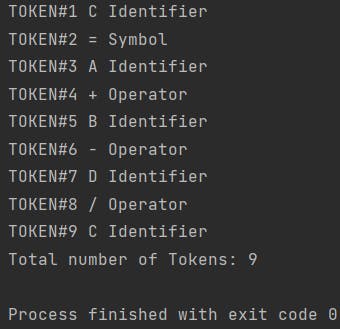
Say we input a string of characters C = A + B - D / C . A token consists of the token type and word itself hence from this stream of characters the tokens. Each token has a type. This introduces an important concept. There are more than 3 types of tokens namely: identifiers which are any general character, operators which carry out mathematically operations and the symbol which is the assign sign or equal sign and more. So the tokens for the characters above are
public class Stringtokenizer3 {
public static void main(String[] args) {
StringTokenizer st = new StringTokenizer("C = A + B - D / C" , " ");
StringTokenizer st1 = new StringTokenizer("C = A + B - D / C" , " ");
...
In the code above the first st object stores the string itself. We then use the st1 object to iterate (count) the number of characters already scanned. Please note, the StringTokenizer method takes in the string that is C = A + B - D / C and the " " empty space as a delimiter that tells the code to separate the string where there is a space.
/*Checks if the String has any more tokens */
int i = 0;
String ttype1= " ";
String C = "C", B = "B", A = "A", EQ = "=", plus = "+", D = "D" , minus ="-", divide = "/";
String C = "C", B = "B", A = "A", EQ = "=", plus = "+", D = "D" , minus ="-", divide = "/";
The line of code above sets the word to expect and to be output in our Symbol Table. A symbol table keeps the names of key entities, identifiers (which are variables, constants, functions and datatypes, etc.), names and keywords (e.g. in Java if, scanner, static...). As you can see the Symbol Table plays a big role on a programming language.
while (st.hasMoreTokens()){
i = i+1;
String name1 = (String) st.nextElement();
if (name1.equals(A) || name1.equals(B) || name1.equals(C) || name1.equals(D)){
ttype1 = "Identifier";}
if (name1.equals(EQ)) { ttype1 = "Symbol";}
if (name1.equals(plus) || name1.equals(minus) || name1.equals(divide)) { ttype1 = "Operator";}
/*Prints the elements from the String*/
System.out.println("TOKEN" + "#" + i + " " + name1 + " " + ttype1);
}
System.out.println("Total number of Tokens: " + st1.countTokens());
}
}
The lines of code above check for the token type of each token and then prints out a Symbol Table. Lastly the number of tokens are printed out. The tokens are finally ready to move on to the parsing phase.
 See you in the next one. https://github.com/Petrus-Nauyoma/stringtokenizer1
See you in the next one. https://github.com/Petrus-Nauyoma/stringtokenizer1